
Introdução
O machine learning (aprendizado de máquina) está revolucionando várias indústrias, tornando-se uma ferramenta indispensável na era digital. Seja na personalização de recomendações em plataformas de streaming, na detecção de fraudes financeiras ou em diagnósticos médicos, o machine learning desempenha um papel crucial. Este artigo fornece uma introdução detalhada aos conceitos fundamentais do machine learning e explora suas principais aplicações.
O Que é Machine Learning?
Machine learning é um subcampo da inteligência artificial (IA) que permite que os sistemas aprendam e melhorem automaticamente com a experiência, sem serem explicitamente programados. Em vez de seguir instruções predefinidas, esses sistemas usam algoritmos para analisar dados, identificar padrões e tomar decisões baseadas nesses dados.
Principais Conceitos de Machine Learning
Algoritmos de Machine Learning: Conjuntos de regras e técnicas usadas para construir modelos que podem prever resultados baseados em dados de entrada.
Modelos de Machine Learning: Representações matemáticas dos dados que são treinadas para fazer previsões ou classificações.
Dados de Treinamento e Teste: Conjuntos de dados usados para treinar e validar os modelos de machine learning.
Supervisionado vs. Não Supervisionado: No aprendizado supervisionado, os modelos são treinados com dados rotulados, enquanto no aprendizado não supervisionado, os modelos buscam padrões em dados não rotulados.
Tipos de Machine Learning
Aprendizado Supervisionado
O aprendizado supervisionado é a abordagem mais comum em machine learning. Nesse tipo de aprendizado, o modelo é treinado usando um conjunto de dados rotulados, o que significa que cada exemplo de treinamento é composto de uma entrada e a saída desejada. O objetivo do modelo é aprender a mapeá-las corretamente.
Classificação
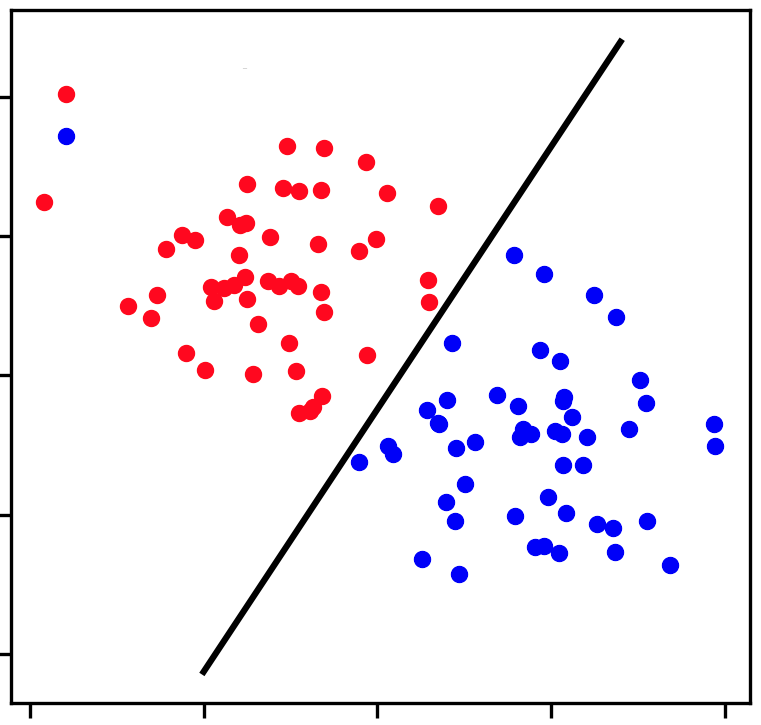
A classificação é uma tarefa de aprendizado supervisionado onde o objetivo é prever a categoria ou classe de um dado exemplo com base em suas características. Exemplos de problemas de classificação incluem:
Classificação de Emails: Determinar se um email é spam ou não spam.
Diagnóstico Médico: Classificar exames médicos como positivos ou negativos para uma doença específica.
Reconhecimento de Imagens: Identificar objetos em uma imagem (por exemplo, distinguir entre um gato e um cachorro).
Os algoritmos comuns usados em tarefas de classificação incluem Árvores de Decisão, K-Nearest Neighbors (KNN), Máquinas de Vetores de Suporte (SVM) e Redes Neurais.
Regressão
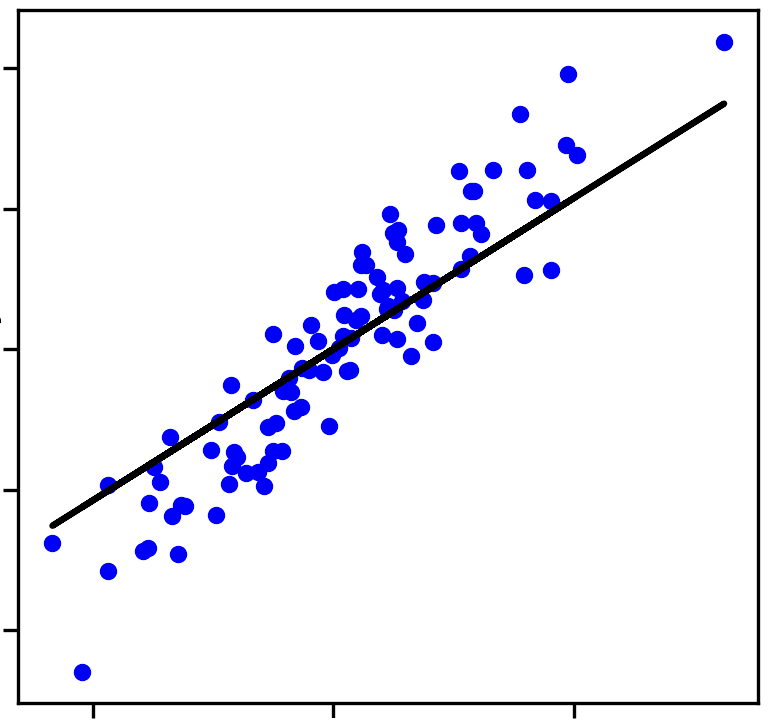
A regressão é outra tarefa de aprendizado supervisionado onde o objetivo é prever um valor contínuo. Exemplos de problemas de regressão incluem:
Previsão de Preços: Estimar o preço de uma casa com base em características como tamanho, localização e número de quartos.
Análise Financeira: Prever o valor futuro de ações ou commodities.
Modelagem de Crescimento: Estimar o crescimento populacional ao longo do tempo.
Algoritmos comuns usados em tarefas de regressão incluem Regressão Linear, Regressão de Ridge, e Redes Neurais.
Aprendizado Não Supervisionado
O aprendizado não supervisionado é usado quando os dados de entrada não possuem rótulos. O objetivo é encontrar padrões ou estruturas ocultas nos dados. Esse tipo de aprendizado é frequentemente usado para análise exploratória de dados.
Agrupamento (Clustering)
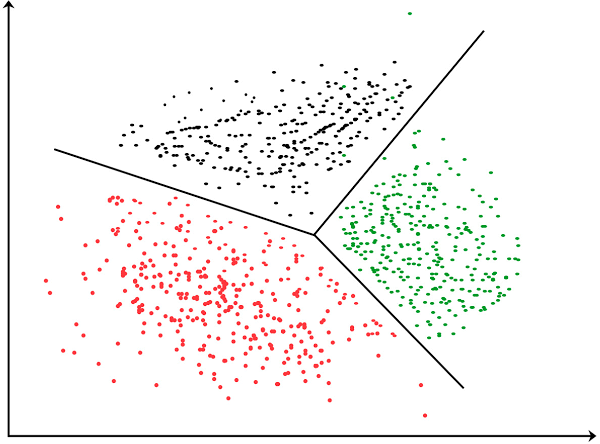
O agrupamento é uma técnica de aprendizado não supervisionado onde o objetivo é dividir os dados em grupos (clusters) de itens semelhantes. Exemplos de aplicações de agrupamento incluem:
Segmentação de Clientes: Agrupar clientes com comportamentos de compra semelhantes para campanhas de marketing direcionadas.
Agrupamento de Imagens: Organizar uma grande coleção de imagens em grupos de imagens semelhantes.
Detecção de Fraudes: Identificar transações anômalas que podem representar atividades fraudulentas.
Algoritmos comuns de agrupamento incluem K-Means, Hierarchical Clustering, e DBSCAN.
Associação
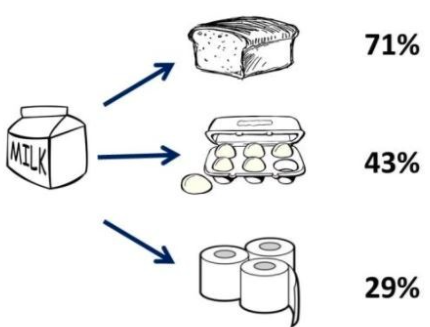
A análise de associação é usada para encontrar regras que descrevem grandes partes dos dados, frequentemente em transações de compra. Exemplos de aplicações incluem:
Cestas de Compras: Identificar produtos que são frequentemente comprados juntos (por exemplo, pão e leite).
Recomendações de Produtos: Sugerir produtos aos clientes com base em suas compras anteriores.
Um algoritmo comum para análise de associação é o Apriori, que é usado para identificar relações frequentes entre itens em grandes bases de dados.
Aprendizado Semi-Supervisionado
O aprendizado semi-supervisionado combina elementos do aprendizado supervisionado e não supervisionado. Ele é útil quando há uma grande quantidade de dados não rotulados e apenas alguns dados rotulados. O objetivo é melhorar o desempenho do modelo utilizando a abundância de dados não rotulados para complementar o treinamento.
Aplicações do Aprendizado Semi-Supervisionado
Reconhecimento de Imagem: Utilizar um pequeno conjunto de imagens rotuladas e uma grande coleção de imagens não rotuladas para treinar um modelo de reconhecimento de imagem mais robusto.
Análise de Texto: Aproveitar uma pequena amostra de documentos rotulados e uma grande quantidade de textos não rotulados para melhorar a classificação de documentos.
Os algoritmos usados em aprendizado semi-supervisionado muitas vezes combinam métodos supervisionados, como Redes Neurais, com técnicas não supervisionadas, como o K-Means, para aprender de maneira eficiente a partir de conjuntos de dados mistos.
Aprendizado por Reforço
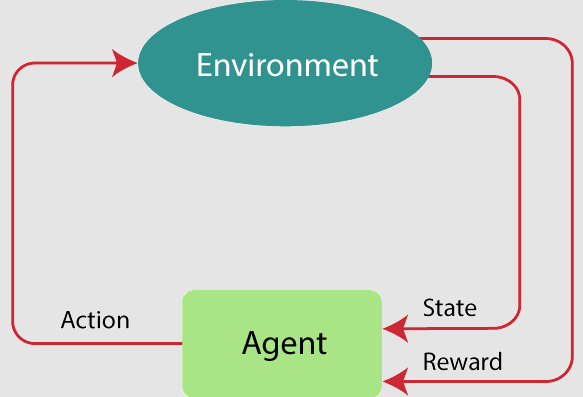
No aprendizado por reforço, um agente aprende a tomar decisões ao interagir com um ambiente. O agente recebe recompensas ou punições com base nas ações que realiza, e o objetivo é maximizar a recompensa cumulativa ao longo do tempo. Esse tipo de aprendizado é utilizado em áreas onde a tomada de decisão sequencial é crucial.
Aplicações do Aprendizado por Reforço
Robótica: Treinar robôs para realizar tarefas complexas, como andar, pegar objetos ou interagir com o ambiente.
Jogos: Desenvolver agentes que podem jogar e vencer jogos de vídeo, como xadrez ou Go, contra adversários humanos ou outros agentes.
Controle de Sistemas: Aplicar em sistemas de controle industrial onde o agente ajusta parâmetros para otimizar o desempenho de um processo.
Algoritmos comuns de aprendizado por reforço incluem Q-Learning, Deep Q-Networks (DQN) e Policy Gradients.
Componentes Fundamentais de Machine Learning
Algoritmos de Machine Learning
Os algoritmos de machine learning são a espinha dorsal do aprendizado de máquina. Eles determinam como os dados são processados e como as previsões são feitas. Vamos explorar alguns dos algoritmos mais comuns:
Regressão Linear: Um dos algoritmos mais simples e amplamente utilizados. É usado para prever um valor contínuo com base em uma variável independente. Por exemplo, prever o preço de uma casa com base em seu tamanho.
Árvores de Decisão: Utilizadas para tarefas de classificação e regressão. Elas dividem os dados em subconjuntos baseados em valores de atributos, criando uma estrutura de árvore que pode ser facilmente interpretada.
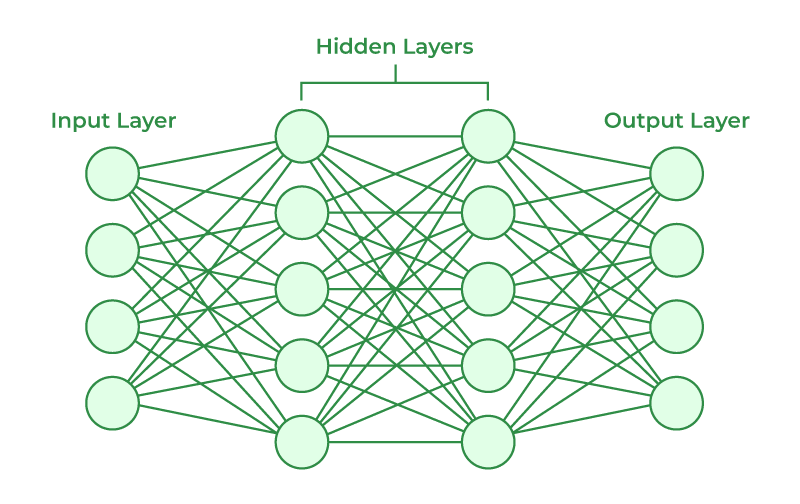
Redes Neurais: Inspiradas na estrutura do cérebro humano, essas redes consistem em camadas de neurônios artificiais. Elas são usadas para tarefas complexas como reconhecimento de imagem e processamento de linguagem natural.
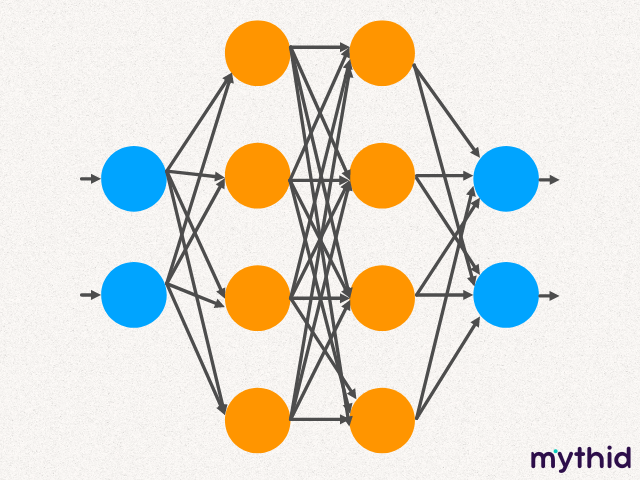
Máquinas de Vetores de Suporte (SVM): Utilizadas principalmente para classificação, essas máquinas criam hiperplanos nos dados de entrada para separar diferentes classes.
Dados de Treinamento e Teste
A qualidade dos dados de treinamento e teste é crucial para o sucesso de um modelo de machine learning. Vamos entender melhor:
Dados de Treinamento: Este conjunto de dados é usado para treinar o modelo, permitindo que ele aprenda os padrões e relações dentro dos dados.
Dados de Teste: Após o treinamento, o modelo é avaliado usando dados de teste, que são novos para o modelo. Isso ajuda a verificar a capacidade do modelo de generalizar e fazer previsões precisas em dados não vistos anteriormente.
Métricas de Avaliação
Avaliar a performance de um modelo de machine learning é essencial para garantir que ele está funcionando corretamente. Algumas das métricas mais comuns incluem:
Acurácia: A proporção de previsões corretas feitas pelo modelo.
Precisão e Recall: Métricas usadas em problemas de classificação para avaliar a relevância e a recuperação dos resultados.
Erro Quadrático Médio (MSE): Utilizado em problemas de regressão para medir a média dos quadrados dos erros ou diferenças entre os valores previstos pelo modelo e os valores reais.
Aplicações de Machine Learning
Personalização de Recomendação
Plataformas como Netflix, Amazon e Spotify usam algoritmos de machine learning para recomendar filmes, produtos e músicas, respectivamente, com base nas preferências e comportamentos dos usuários. Esses sistemas analisam os dados de interação dos usuários e fazem previsões sobre o que pode interessar a eles no futuro.

Diagnóstico Médico
Na área da saúde, o machine learning é utilizado para diagnosticar doenças a partir de exames e imagens médicas. Algoritmos treinados em grandes bases de dados podem identificar padrões e anomalias que são indicativos de condições médicas específicas, como câncer ou doenças cardíacas, muitas vezes com precisão superior à dos médicos humanos.
Detecção de Fraudes

Bancos e instituições financeiras usam machine learning para monitorar transações em tempo real e identificar atividades suspeitas. Algoritmos podem detectar padrões incomuns que podem indicar fraude, permitindo uma resposta rápida para prevenir perdas financeiras.
Processamento de Linguagem Natural (NLP)
O processamento de linguagem natural (NLP) é um subcampo do machine learning que foca na interação entre computadores e a linguagem humana. O objetivo é permitir que os computadores compreendam, interpretem e gerem a linguagem natural de maneira útil. Aqui estão algumas das principais aplicações do NLP:
Assistentes Virtuais
Assistentes virtuais como Alexa, Siri e Google Assistant usam NLP para entender comandos de voz, responder perguntas e realizar tarefas. Esses sistemas são capazes de processar a linguagem falada, converter em texto, analisar o contexto e fornecer respostas apropriadas.
Tradução Automática
Serviços de tradução como Google Translate utilizam algoritmos de NLP para traduzir texto entre diferentes idiomas. Esses sistemas analisam a estrutura gramatical e semântica do texto de origem e geram traduções precisas e contextualmente corretas no idioma de destino.
Análise de Sentimento
A análise de sentimento é uma técnica que utiliza NLP para determinar as emoções expressas em um texto. Empresas usam essa técnica para monitorar a opinião pública sobre seus produtos e serviços nas redes sociais e em avaliações online.
Chatbots
Chatbots são programas de computador que utilizam NLP para conversar com usuários em linguagem natural. Eles são amplamente usados em atendimento ao cliente para fornecer suporte 24/7, responder perguntas frequentes e resolver problemas comuns.
Veículos Autônomos
Os veículos autônomos são um dos avanços mais impressionantes impulsionados pelo machine learning. Empresas como Tesla, Waymo e Uber estão desenvolvendo carros autônomos que utilizam uma combinação de sensores, câmeras e algoritmos de machine learning para navegar e tomar decisões de direção em tempo real.
Sensores e Percepção
Os veículos autônomos estão equipados com uma variedade de sensores, como LIDAR, radar e câmeras, que coletam dados sobre o ambiente ao redor do veículo. Esses sensores permitem que o carro detecte e identifique objetos, pedestres e outros veículos.
Processamento e Decisão
Os dados coletados pelos sensores são processados por algoritmos de machine learning que interpretam o ambiente, identificam possíveis obstáculos e tomam decisões de navegação. Esses sistemas são projetados para operar com alta precisão e segurança, mesmo em situações complexas de tráfego.
Condução Autônoma
Os veículos autônomos possuem diferentes níveis de autonomia, desde assistência ao motorista até a condução totalmente autônoma. Empresas estão continuamente aprimorando essas tecnologias para tornar os carros autônomos mais seguros e eficientes.
Análise Preditiva
A análise preditiva utiliza machine learning para fazer previsões sobre eventos futuros com base em dados históricos. Essa técnica é amplamente usada em negócios para planejar estratégias e tomar decisões informadas.
Previsão de Vendas
Empresas utilizam modelos preditivos para analisar dados históricos de vendas e prever futuras demandas de produtos. Isso ajuda na gestão de estoque e na elaboração de estratégias de marketing mais eficazes.
Gestão de Risco
Na indústria financeira, a análise preditiva é usada para avaliar riscos e prever tendências de mercado. Bancos e instituições financeiras utilizam esses modelos para tomar decisões sobre investimentos e concessão de créditos.
Manutenção Preditiva
Indústrias utilizam a manutenção preditiva para monitorar o estado de equipamentos e prever falhas antes que ocorram. Isso reduz o tempo de inatividade e os custos de manutenção, melhorando a eficiência operacional.
Como Começar com Machine Learning
Conhecimentos Necessários
Para iniciar no mundo do machine learning, é essencial ter uma base sólida em matemática, especialmente em áreas como álgebra linear, cálculo e estatística. Além disso, habilidades de programação, particularmente em Python, são fundamentais, pois muitas bibliotecas e frameworks de machine learning são construídos nessa linguagem.
Ferramentas e Bibliotecas

Existem diversas ferramentas e bibliotecas que facilitam o desenvolvimento de projetos de machine learning. Aqui estão algumas das mais populares:
Scikit-learn: Uma biblioteca de aprendizado de máquina para Python que oferece ferramentas simples e eficientes para análise de dados e modelagem preditiva.
TensorFlow: Desenvolvida pelo Google, essa plataforma de código aberto é amplamente usada para construir e treinar modelos de machine learning.
Keras: Uma API de alto nível construída sobre o TensorFlow, que facilita a criação e treinamento de redes neurais.
Cursos e Recursos
Para aqueles que desejam aprender mais sobre machine learning, existem muitos cursos e recursos disponíveis online. Algumas recomendações incluem:
Coursera: Oferece cursos de machine learning de instituições renomadas, como o curso de Andrew Ng sobre aprendizado de máquina.
edX: Plataforma que oferece cursos de machine learning de universidades como Harvard e MIT.
Kaggle: Uma plataforma para competições de ciência de dados que oferece tutoriais, datasets e uma comunidade ativa.
Desafios e Considerações Éticas
Desafios Técnicos
O desenvolvimento e implementação de modelos de machine learning enfrentam vários desafios técnicos:
Qualidade dos Dados: A precisão dos modelos depende fortemente da qualidade dos dados de treinamento. Dados incompletos ou enviesados podem levar a previsões incorretas.

Complexidade dos Modelos: Modelos mais complexos, como redes neurais profundas, podem ser difíceis de treinar e ajustar corretamente.
Computação: Modelos complexos podem exigir recursos computacionais significativos, tornando necessário o uso de hardware especializado, como GPUs.
Considerações Éticas
Com o crescente uso de machine learning, surgem várias questões éticas que devem ser cuidadosamente consideradas para garantir que a tecnologia seja utilizada de forma responsável e justa. Aqui estão algumas das principais preocupações éticas associadas ao machine learning:
Viés e Discriminação
Algoritmos de machine learning podem perpetuar ou até amplificar vieses presentes nos dados de treinamento. Se os dados utilizados para treinar um modelo contêm vieses históricos ou sociais, esses vieses podem ser incorporados e replicados pelo modelo, levando a decisões injustas ou discriminatórias.
Para mitigar esses riscos, é crucial adotar práticas de desenvolvimento ético, como:
Auditoria de Dados: Avaliar e limpar os dados de treinamento para remover vieses.
Treinamento e Validação Justa: Usar técnicas de reamostragem e outras abordagens para garantir que o modelo não favoreça nenhum grupo específico.
Monitoramento Contínuo: Implementar processos contínuos de monitoramento e auditoria dos modelos em produção para identificar e corrigir vieses emergentes.
Privacidade
O uso de dados pessoais em modelos de machine learning levanta preocupações significativas sobre a privacidade dos indivíduos. É essencial garantir que os dados sejam coletados, armazenados e utilizados de maneira a proteger a privacidade dos usuários.
Para proteger a privacidade, é recomendável:
Anonimização de Dados: Remover ou ofuscar informações identificáveis nos conjuntos de dados.
Consentimento Informado: Obter consentimento explícito dos usuários antes de coletar e usar seus dados.
Segurança de Dados: Implementar medidas robustas de segurança para proteger os dados contra acessos não autorizados e violações.
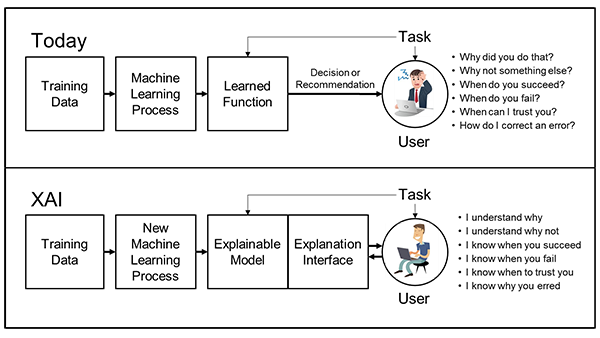
Transparência e Explicabilidade
Modelos de machine learning, especialmente os mais complexos, podem ser difíceis de interpretar. Garantir a transparência e a capacidade de explicação dos modelos é essencial para construir confiança e garantir a compreensão dos processos de tomada de decisão.
Para promover a transparência e a explicabilidade:
Modelos Interpretabis: Sempre que possível, usar modelos que sejam mais fáceis de interpretar, como árvores de decisão ou regressões lineares.
Ferramentas de Explicabilidade: Utilizar ferramentas como LIME (Local Interpretable Model-agnostic Explanations) e SHAP (SHapley Additive exPlanations) para explicar as decisões dos modelos complexos.
Documentação: Manter uma documentação detalhada sobre como os modelos foram desenvolvidos, treinados e validados.
Futuro do Machine Learning
O futuro do machine learning é promissor, com avanços contínuos que prometem transformar ainda mais diversos setores. Aqui estão algumas tendências emergentes:
Aprendizado Profundo (Deep Learning)
O aprendizado profundo está evoluindo rapidamente e sendo aplicado em áreas complexas como visão computacional, processamento de linguagem natural e jogos. Redes neurais profundas estão permitindo avanços significativos em reconhecimento de padrões e tomada de decisões.
Aprendizado Federado
O aprendizado federado permite que modelos de machine learning sejam treinados em vários dispositivos descentralizados usando dados locais, sem a necessidade de centralizar os dados. Isso melhora a privacidade e a segurança dos dados enquanto permite treinamento eficiente.
IA Explicável (Explainable AI)
A IA explicável visa aumentar a transparência e a interpretabilidade dos modelos de machine learning. Novas técnicas estão sendo desenvolvidas para fornecer explicações claras e compreensíveis sobre como os modelos chegam a determinadas decisões.
Machine Learning AutoML
O AutoML (aprendizado de máquina automatizado) facilita o desenvolvimento de modelos de machine learning, automatizando tarefas complexas de pré-processamento de dados, seleção de algoritmos e ajuste de hiperparâmetros. Isso torna o machine learning mais acessível a pessoas com menos experiência técnica.

Integração com Internet das Coisas (IoT)
A integração de machine learning com a Internet das Coisas (IoT) está permitindo a criação de sistemas inteligentes que podem analisar dados em tempo real e tomar decisões automáticas. Isso está sendo amplamente aplicado em casas inteligentes, cidades inteligentes e indústrias conectadas.
Conclusão
O machine learning está revolucionando diversos setores, desde a saúde até a tecnologia, proporcionando soluções inovadoras para problemas complexos. Com a crescente disponibilidade de dados e o avanço das técnicas de aprendizado, as aplicações de machine learning continuarão a expandir, trazendo benefícios significativos à sociedade.
Para aqueles que desejam iniciar sua jornada no machine learning, é essencial adquirir conhecimentos sólidos em matemática e programação, além de explorar as diversas ferramentas e recursos disponíveis. À medida que essa tecnologia avança, questões éticas e desafios técnicos devem ser cuidadosamente considerados para garantir um uso justo e responsável.
Com uma base sólida e um entendimento claro das possibilidades e limitações, qualquer um pode começar a explorar o fascinante mundo do machine learning e contribuir para o seu desenvolvimento contínuo.



Deixe um comentário